Estruturas de controle
No meio dos anos 60, matemáticos provaram que qualquer programa, não importa o quão complicado ele seja, pode ser construído usando uma ou mais de apenas três estruturas, que são: sequência, seleção e iteração.
Na sequência, as ações são feitas uma após a outra e o fluxo do programa é linear. Uma vez que você começa uma série de ações em uma sequência, você deve continuar passo-a-passo até que a sequência termine.
Na seleção, que também é chamada de estrutura de decisão, uma ação ou um grupo de ações é realizada baseado no cumprimento ou não de uma condição ou de um grupo de condições. Já na iteração, também chamada de estrutura de repetição, uma instrução ou uma sequência de instruções é seguida enquanto uma condição for verdadeira. Diferentemente da sequência, na seleção e na iteração, o fluxo não é linear. Exatamente por isso, essas duas estruturas são chamadas de estruturas de controle, porque elas controlam o fluxo do programa.
Estruturas de seleção
Estrutura se
Vamos começar com uma estrutura bem simples: a estrutura se, que é o if das linguagens
de programação.
inteiro x = 4
se (x == 4) {
escreva("x é igual a 4")
}Essa é uma estrutura de seleção muito simples. Ela simplesmente recebe uma condição entre parênteses, e se ela for verdadeira, o código que está dentro das chaves é executado. A sintaxe dela no Portugol é bem parecida com a sintaxe usada pelas linguagens de programação.
Perceba que eu utilizei == para verificar se x é igual a 4. Esse é um operador de comparação e ele
checa se o operando da esquerda é igual ao operando da direita.
Observe que eu digitei um Tab no pseudocódigo que está dentro da estrutura de controle. Isso que eu
fiz se chama indentação. Ela mostra a hierarquia dos componentes do algoritmo. No caso, ela deixa mais claro que
a instrução escreva() pertence ao se.
Estrutura senao
Ainda no exemplo anterior, o que faríamos se quiséssemos mostrar uma mensagem caso a variável x não
fosse igual a 4? Para isso, existe uma estrutura de controle chamada senao. É o else
das linguagens de programação. Ela deve ser colocada imediatamente depois de um se ou de um
senao se, que você vai ver daqui a pouco. Veja como ficaria o código com o senao:
inteiro x = 4
se (x == 4) {
escreva("x é igual a 4")
}
senao {
escreva("x é diferente de 4")
}
Veja que a estrutura dela é parecida com o se. A diferença é que o senao não tem
nenhuma condição para ser testada. Ele é executado somente quando o se não é executado. Altere o
valor de x para 3 para que o senao seja executado.
Fluxograma
Mostrei como as estruturas de decisão se e senao podem ser representadas em
pseudocódigo. Agora, vou mostrar como representá-las em fluxogramas. Se você não viu o
tutorial de fluxogramas, recomendo fortemente que você veja, já que só vou explicar
os elementos novos.
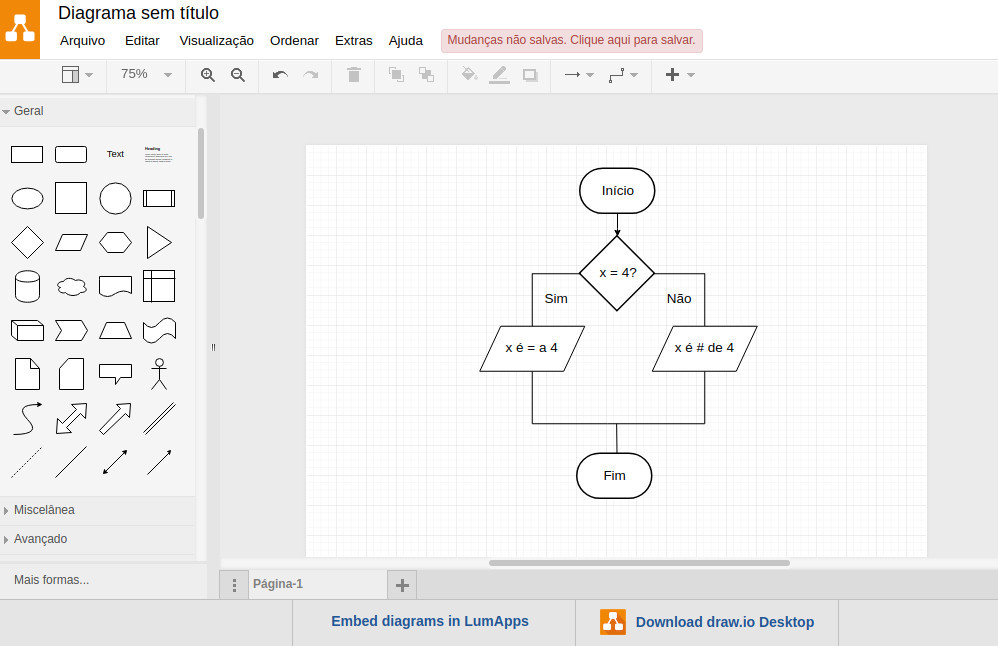
Veja como ficaria a estrutura de controle se representada em um fluxograma:
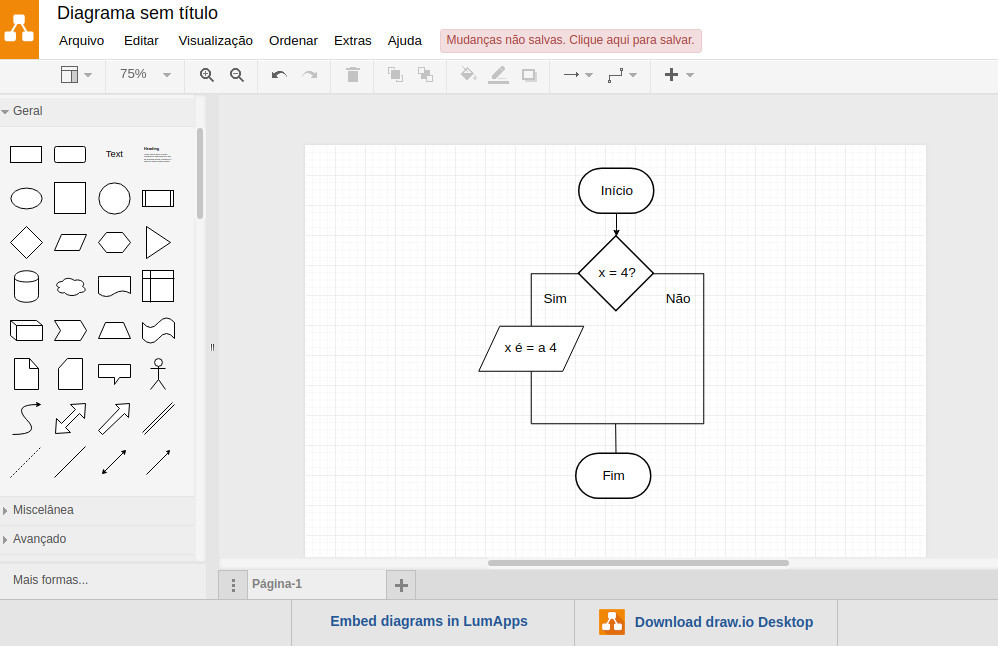
O losango é usado para expressar a condição da estrutura. Ele sempre deve ter duas ramificações, mesmo que não seja feito nada em uma delas. Para maior clareza, adiciona-se um Sim e um Não a cada ramificação. O losango é um elemento da aba Fluxograma:
As linhas das ramificações foram criadas usando os retângulos parciais que contém os lados superior e esquerdo, e inferior e direito. Eles estão na aba Básico:
Por fim, a linha é um elemento da aba Geral:
O algoritmo que contém a estrutura senao é praticamente igual ao anterior. A diferença é que ele
contém um output na ramificação do Não:
Estrutura senao se
Essa estrutura precisa vir imediatamente após um se ou um senao se. Ela é executada
quando a estrutura anterior não tem o seu código executado. Até esse ponto ela é igual ao senao. A
diferença é que nem sempre o senao se será executado, porque ele tem uma condição. Se ela for
verdadeira, ele é executado. Nesse ponto, ele é igual ao se. Então, podemos dizer que essa
estrutura pega um pouco das duas estruturas. Inclusive, o nome dela indica isso.
Vamos pensar em um algoritmo que retorna a classificação do IMC de acordo com o valor dele:
real imc
leia(imc)
se (imc < 18.5) {
escreva("Abaixo do peso")
}
senao se (imc < 25) {
escreva("Peso normal")
}
senao se (imc < 30) {
escreva("Sobrepeso")
}
senao {
escreva("Obesidade")
}
A classificação real é um pouco mais complexa, mas eu simplifiquei para facilitar. Execute o programa algumas
vezes usando valores diferentes e veja os resultados. Perceba que eu usei um operador de comparação novo: o
<. Ele faz exatamente o que você pensou: verifica se o primeiro operando é menor do que o
segundo. Vou falar mais sobre operadores de comparação
depois.
Aninhamento
Vamos imaginar que eu queira fazer um algoritmo que verifique o sexo e a altura de uma pessoa e exiba uma mensagem dizendo Baixo (a) ou Alto (a). Uma das formas de escrevê-lo é essa:
logico sexo
real altura
leia(sexo)
leia(altura)
se (sexo == verdadeiro e altura < 1.62) {
escreva("Baixa")
}
senao se (sexo == verdadeiro e altura >= 1.62) {
escreva("Alta")
}
se (sexo == falso e altura < 1.75) {
escreva("Baixo")
}
senao se (sexo == falso e altura >= 1.75) {
escreva("Alto")
}
O algoritmo funciona, mas é claro que existem formas bem melhores e mais simples de escrevê-lo. Mas, para
propósitos didáticos, eu vou reescrevê-lo só pra mostrar um conceito novo pra vocês. Antes da reescrita, vejam
que eu utilizei uma coisa nova: o operador e, que é um operador lógico usado para unir duas
condições. Basicamente, ele exige que as duas condições que ele conecta sejam verdadeiras. Vou falar mais sobre
operadores lógicos depois.
Voltando à reescrita, vejam que há uma repetição de operadores de comparação: o sexo == verdadeiro
está na primeira e na segunda estrutura, e o sexo == falso está na terceira e na quarta estrutura.
Uma das formas de eliminar isso seria a seguinte:
logico sexo
leia(sexo)
real altura
leia(altura)
se (sexo == verdadeiro) {
se (altura < 1.62) {
escreva("Baixa")
}
senao {
escreva("Alta")
}
}
senao {
se (altura < 1.75) {
escreva("Baixo")
}
senao {
escreva("Alto")
}
}Veja que eu coloquei estruturas de controle dentro de outras estruturas de controle. Isso que eu fiz se chama aninhamento. Eu poderia fazer mais níveis de aninhamento, ou seja, colocar mais estruturas de controle dentro dessas estruturas internas. Só que isso não é preciso, e não é recomendado, porque deixa o código complexo. Fomos até o 2º nível de aninhamento. O ideal é ir no máximo até o 3º nível.
O código ficou mais simples de entender e até passou a testar menos condições, com uma performance melhor. É claro que tem maneiras melhores de escrever esse algoritmo, mas eu fiz dessa forma só pra explicar pra você o conceito de aninhamento.
Agora que vimos aninhamento, é importante fazer algumas observações: toda estrutura precisa ser fechada; estruturas de níveis mais externos nunca podem ser fechadas antes de estruturas de níveis mais internos que estão contidas nela.
Se vs senao se
Vamos debater um pouco mais as diferenças entre o se e o senao se. O
senao se só é avaliado se as instruções da estrutura anterior a ele não forem executadas. Já o
se sempre é avaliado. Essa diferença, além de poder mudar o resultado final, pode causar diferenças
na performance do programa também.
Como o senao se muitas vezes não é avaliado, essa opção tem uma performance melhor. Mas a decisão
sobre qual utilizar depende, na verdade, do que você quer fazer. Vou mostrar um exemplo de utilização da
estrutura incorreta:
real nota_aluno
leia(nota_aluno)
se (nota_aluno >= 0.0 e nota_aluno < 7.0) {
escreva("Insuficiente\n")
}
se (nota_aluno >= 7.0) {
escreva("Regular\n")
}
se (nota_aluno >= 8.0) {
escreva("Bom\n")
}
se (nota_aluno >= 9.0 e nota_aluno <= 10.0) {
escreva("Ótimo\n")
}
senao {
escreva("Nota inválida\n")
}
Rode o exemplo e digite uma nota entre 9 e 10. O aluno receberá vários conceitos. Isso acontece porque o
se foi usado quando na verdade o senao se deveria ser usado. Um aluno não pode receber
mais de um conceito. Por isso, se uma das condições for aceita, nada mais deve ser testado. Assim, o mais
correto seria usar apenas um se e depois, usar senao se e o senao para
finalizar. Sugiro que você modifique o programa fazendo essas alterações, e depois digite novamente uma nota
entre 9 e 10. Se você fizer as alterações corretamente, o aluno sempre receberá apenas um conceito.
Estrutura escolha-caso
Essa estrutura é equivalente ao switch das linguagens de programação. Nessa estrutura, você pega
uma variável qualquer e cria branches para os valores que a variável pode ter. Exemplo:
inteiro titulos
leia(titulos)
escolha (titulos) {
caso 0:
escreva("Não ganhou nada")
pare
caso 1:
escreva("Campeão")
pare
caso 2:
escreva("Bicampeão")
pare
caso contrario:
escreva("Mito")
}Cada caso tem que ter exatamente um valor específico. Há linguagens de programação que aceitam um grupo de valores. O Portugol suporta apenas um valor.
Não dá para usar operadores de comparação como nas estruturas de seleção, nem operadores lógicos. Nesse sentido,
o switch é mais limitado. Quando o pare é usado nos casos (exceto no último), o
primeiro caso funciona como se fosse um se e os casos seguintes funcionam como se fossem
senao se, só que com as limitações que eu citei.
O caso contrario é como se fosse um senao. Ele é acionado quando o programa não entra
em nenhum dos outros casos. É opcional.
Note que eu coloquei a instrução pare em todos os casos, com exceção do último. Porque eu fiz isso?
Pro algoritmo não testar os outros casos. Você pode colocar dois casos com o mesmo valor por engano. Sem o
pare, o algoritmo entraria nos dois casos. Seria um erro lógico. Além disso, mesmo que você não
cometa esse erro lógico, se você não colocar o pare, o algoritmo vai testar os outros casos
enquanto ele não encontrar um pare. Colocar o pare impede que ele continue testando os
outros casos desnecessariamente, melhorando a performance do algoritmo.
Vale lembrar que o valor testado não precisa ser um inteiro. Pode ser uma string também. Porém, no Portugol, só são suportados os tipos inteiro e caractere.
Estruturas de repetição
Essa estrutura repete ações enquanto uma condição permanecer verdadeira. Essa condição pode ser tanto uma condição simples, como também uma condição composta, que nada mais é do que um grupo de condições. Cada ciclo do loop é chamado de iteração.
Estrutura enquanto
Um tipo de loop muito comum é o enquanto, que é o while das linguagens de programação.
Veja abaixo um algoritmo onde ele está presente:
inteiro numero = 1
inteiro cuboNumero
enquanto (numero != 0) {
escreva("Digite um número inteiro\n")
leia(numero)
cuboNumero = numero * numero * numero
escreva("O cubo do número é ", cuboNumero, "\n")
}Antes da primeira iteração, as condições do loop são avaliadas. Por isso, esse tipo de loop é chamado de repetição pré-testada. Por isso, a variável numero recebeu o valor 1. Se ela tivesse recebido o valor 0, o programa nem entraria no loop.
O loop continua sendo executado enquanto a sua condição permanecer verdadeira, ou seja, enquanto o valor da variável numero for diferente de 0. A cada iteração, todas as instruções do loop são executadas.
Do-while
Um outro tipo de loop é o do-while (faz-enquanto). Nesse tipo de loop, pelo menos uma iteração
ocorre, porque a avaliação da condição se dá após a execução da iteração. Por isso, esse tipo de repetição é
chamada de repetição pós-testada. Veja como o algoritmo anterior poderia ser representado
usando essa estrutura:
inteiro numero
inteiro cuboNumero
faca {
escreva("Digite um número inteiro\n")
leia(numero)
cuboNumero = numero * numero * numero
escreva("O cubo do número é ", cuboNumero, "\n")
} enquanto (numero != 0)Note que aqui não é necessário atribuir um valor inicial para a variável numero que seja diferente de 0, porque a primeira iteração está garantida. Por isso, esse algoritmo ficou mais adequado a esse tipo de situação, até porque evitou a necessidade da atribuição de um valor inicial à variável usada na condição.
Mesclando estruturas
Já mostrei um exemplo onde eu aninhei estruturas de seleção. Também é possível aninhar estruturas de repetição dentro de outras estruturas de repetição ou em estruturas de seleção e vice-versa. Veja o exemplo abaixo:
inteiro numero
faca {
escreva("Digite um número inteiro\n")
leia(numero)
se (numero %2 == 0) {
escreva("O número que você digitou é par\n")
}
senao {
escreva("O número que você digitou é ímpar\n")
}
} enquanto (numero != 0)Estrutura for
A maioria das linguagens de programação suportam o for. Ele define três ações em uma sintaxe
compacta. Essas ações são inicialização, condição e atualização. A inicialização é usada para inicializar
variáveis e é a primeira coisa que é feita no for. Só é feita no começo. A condição é feita antes
de cada iteração, inclusive a primeira. A atualização é feita após cada iteração.
O uso mais comum de um for é inicializar uma variável, que é chamada de
variável de controle, testá-la na condição do for e depois atualizá-la. Por causa do uso da
variável de controle, esse tipo de repetição é chamado também de
repetição com variável de controle.
para (inteiro i = 1; i <= 10; i++) {
escreva(i, "\n")
}Você também pode omitir a inicialização e a atualização:
inteiro i = 1
para (; i <= 10; ) {
escreva(i, "\n")
i++
}Não é possível omitir a condição no Portugol Studio, embora algumas linguagens de programação, como o PHP, permitam a omissão da condição.
A atualização também pode ser chamada de step value. Seu valor pode ser positivo ou negativo. Se for positivo, é um incremento. Se for negativo, é um decremento.
É possível usar o while para alcançar o mesmo efeito do for:
inteiro i = 1
enquanto (i <= 10) {
escreva(i, "\n")
i++
}
Veja que, pra esse tipo de situação, é muito melhor usar o for, já que é uma solução mais compacta
e elegante.
Agora, eu vou inverter o exemplo, pra contar de 10 até 1. Aí, eu vou usar o decremento ao invés do incremento.
Veja a diferença do mesmo exemplo feito com o for e com o enquanto:
inteiro i = 10
enquanto (i >= 1) {
escreva(i, "\n")
i--
}
para (i = 10; i >= 1; i--) {
escreva(i, "\n")
}Estrutura para cada
Uma outra estrutura de repetição é o para cada, que é o for each das linguagens de
programação. Essa estrutura executa instruções para cada item de uma coleção. Então, há uma iteração para cada
item. Por isso, essa estrutura é chamada de iteração de coleção. A coleção é basicamente um
conjunto de dados quaisquer, não importa o tipo. Ou seja, uma coleção não é necessariamente uma array.
O para cada não é suportado pelo Portugol, mas uma maneira de representá-la em um pseudocódigo é a
seguinte:
para cada (item em coleção) {
instruções
}Exemplo:
para cada (carro em carrosJogador) {
instruções
}
Lembrando que, como eu falei, o Portugol não suporta essa estrutura de repetição, até porque essa estrutura não
é tão universal como as outras, não é essencial como um if ou um while e é mais
recente. Ela é mais suportada em linguagens mais novas, como o PHP. Veja:
foreach ($carrosJogador as $carro) {
// Instruções
}
Veja que a sintaxe do foreach do PHP é um pouco diferente. Ela especifica primeiro a coleção e
depois o item dela.
O que você faz em um foreach, você também pode fazer em um for, mas se a linguagem que
você usa tem um foreach, eu recomendo usá-lo, porque é uma solução mais simples, elegante e
legível.
Pare e continue
Duas instruções muito comuns em linguagens de programação são o pare (que é o break
das linguagens de programação) e o continue. Elas são usadas em estruturas de repetição, então eu
posso usar em qualquer uma das estruturas de repetição que eu mostrei aqui. Além disso, o pare
também é usado na estrutura de decisão escolha-caso.
O continue não é suportado no Portugol. Então, vamos ver o pare, que é usado em estruturas de
repetição para interrompê-las:
para (inteiro i = 10; i >= 1; i--) {
escreva(i, "\n")
se (i == 5) {
pare
}
}O continue é usado para pular para a próxima iteração do loop. Veja abaixo um exemplo de uso dele em C++:
for (int i = 0; i < 10; i++) {
if (i == 7) {
continue;
}
// Instruções
}